
参考链接
1.abstract
1.0 摘要,论文导读
摘要主要内容:
深度神经网络很难训练,我们使用residual(残差结构)使得网络训练比之前容易很多在ImageNet上使用了152层的ResNet,比VGG多8倍,但是计算复杂度更低,最终赢下了ImageNet2015的分类任务第一名,并演示了如何在cifar-10上训练100-1000层的网络。(通常赢下ImageNet比赛且提出很不一样网络架构、方法的文章会被追捧。)
对很多任务来说,深度是非常重要的。我们仅仅是把之前的网络换成残差网络,在coco数据集上就得到了28%的改进。同样也赢下了ImageNet目标检测、coco目标检测和coco segmentation的第一名。
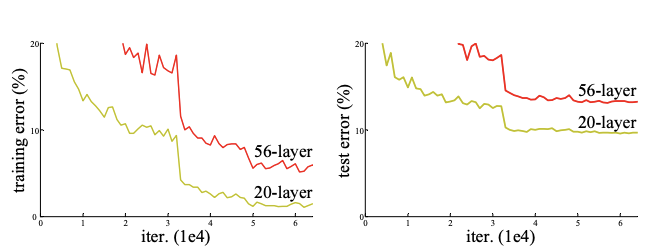
上面这张图是没有使用残差结构的网络,更深的层训练误差比浅层更高,即深层网络其实是训练不动的。下面这张图,是是否使用resnet结构的网络效果对比图。可以看到右侧使用残差结构后,34层的网络训练和测试的误差都更低。
| Layers\Model | Plain | ResNet |
|---|---|---|
| 18 layers | 27.94 | 27.88 |
| 34 layers | 28.54 | 25.03 |
2.导论
2.1 为什么提出残差结构
深度卷积神经网络是非常有效的,因为可以堆叠很多层,不同层可以表示不同level的特征。但是学一个好的网络,就是简简单单的把所有网络堆在一起就行了吗?如果这样,网络做深就行了。
我们知道,网络很深的时候,容易出现梯度消失或者梯度爆炸,解决办法之一是一个好的网络权重初始化,使权重不能太大也不能太小;二是加入一些normalization,比如BN。这样可以校验每个词之间的输出,以及梯度的均值和方差,这样比较深的网络是可以训练的(可以收敛)。但同时有一个问题是,深层网络性能会变差,也就是精度会变差。
深层网络性能变差,不是因为网络层数多、模型变复杂而过拟合,因为训练误差也变高了。那为什么会这样呢?从理论上来说,往一个浅层网络中加入一些层,得到一个深一些的网络,后者的精度至少不应该变差。因为后者至少可以学成新加的层是identity mapping,而其它层直接从前者复制过来。但是实际上做不到,SGD优化器无法找到这个比较优的解。
1 | identity mapping可以理解成恒等映射吧,也就是网络输入x,输出也是x。网络权重简单学成输入特征的1/n。 |
所以作者提出,显式地构造一个identity mapping,使得深层模型的精度至少不会变得更差。作者将其称为deep residual learning framework。
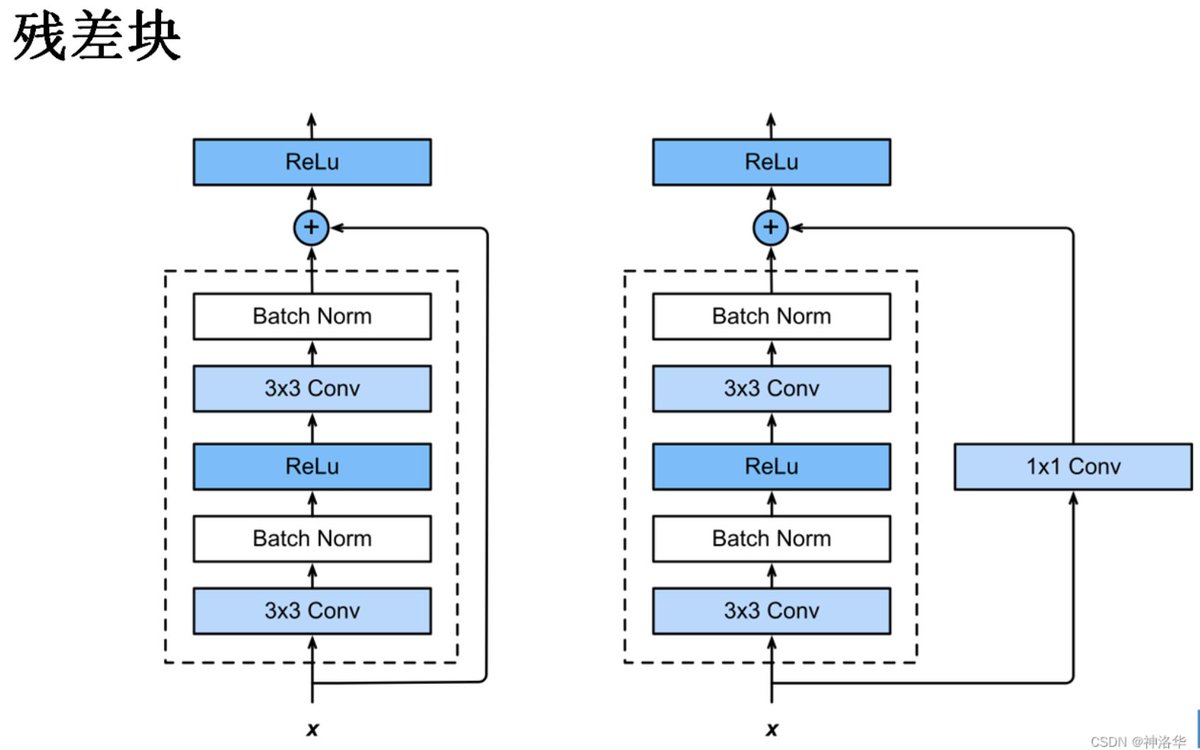
假设我们要学的是 H(x),在原有层上添加一些新的层时,新的层不是直接学 H(x),而是学习 H(x) - x,这部分用 F(x) 表示。(其中,x 是原有层的输出。)即,新加入的层不用全部重新学习,而是学习原来已经学习到的 x 和真实的 H(x) 之间的残差就行。最后模型的输出是 F(x) + x。这种新加入的层就是residual,结构如下图所示:
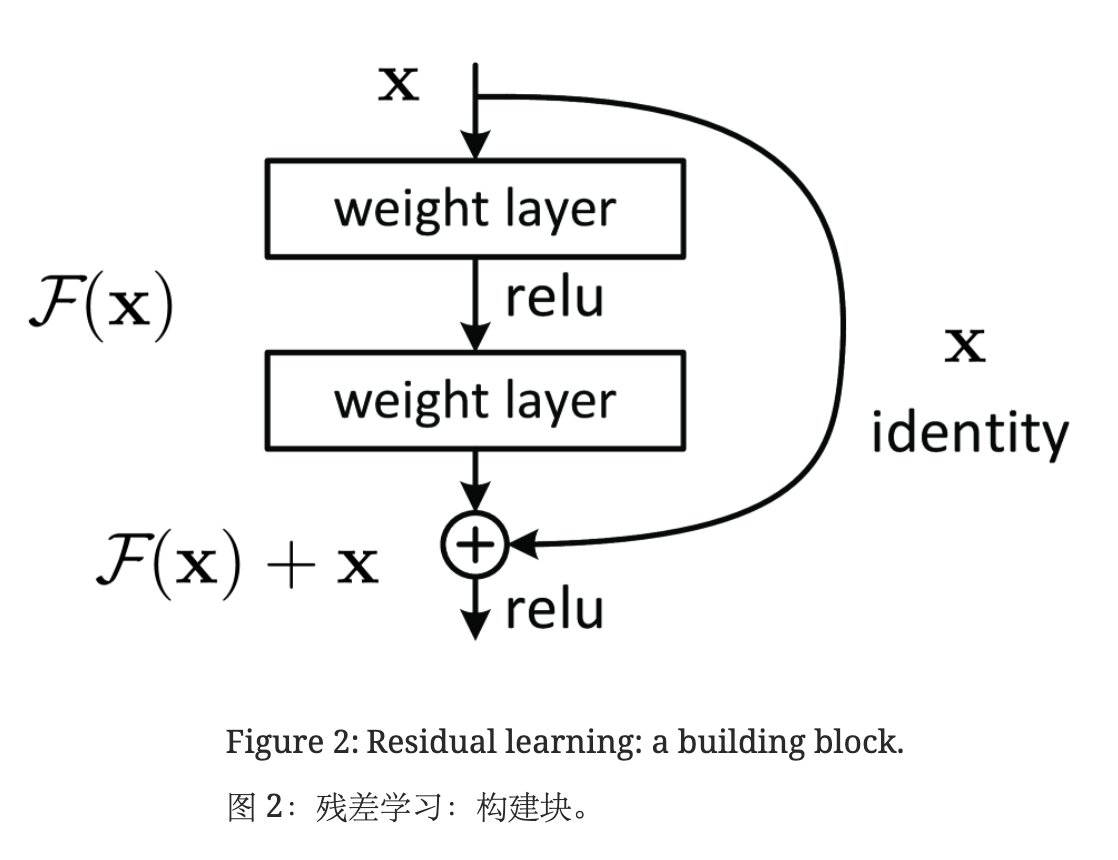
F(x) + x 在数学上就是直接相加,在神经网络中是通过shortcut connections实现(shortcut就是跳过一个或多个层,将输入直接加到这些跳过的层的输出上)。shortcut其实做的是一个identity mapping(恒等映射),而且这个操作不需要学习任何参数,不增加模型的复杂度。就多了一个加法,也不增加计算量,网络结构基本不变,可以正常训练。
2.2 实验验证
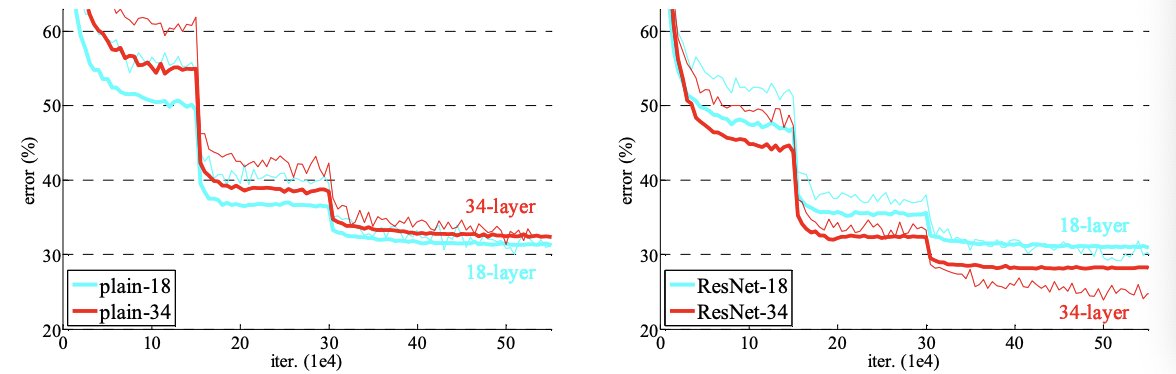
接下来作者在imagenet上做了一系列实验进行验证。结果表明,加了残差的网络容易优化,而且网络堆的更深之后,精度也会提高,所以赢下了比赛。在cifar-10上,作者尝试了训练超过1000层的网络。至此,论文的核心就讲完了,下面就是ResNet网络的设计。
3.相关工作
ResNet并不是第一个提出residual的概念。 最早的线性模型的解法就是通过不断迭代residual来求解的。在机器学习中,GBDT通过残差residual不断学习,把弱分类器叠加起来,形成强分类器。不同之处在于,GBDT是在label上做残差,而ResNet是在特征上做残差。
ResNet也不是第一个提出shortcut的。 比如在highway networks中就已经使用了shortcut,但其实现方式更为复杂,不仅仅是简单的加法。
一篇文章之所以成为经典,并不一定是因为它原创性地提出了许多新概念。有时,它的经典之处在于将多个已有概念巧妙地结合在一起,从而有效解决问题。甚至有时大家都可能忘记了之前有谁做过类似的工作。许多想法可能早已被前人提出并发表,但重要的是,这些想法可以被用来解决新的问题,使得旧技术在新的应用中展现出新的意义。
ResNet34比起VGG19,计算复杂度更低,只有前者的18%。其它是一些训练的细节,学习率优化器等等之类,就不细讲了。
4.实验部分
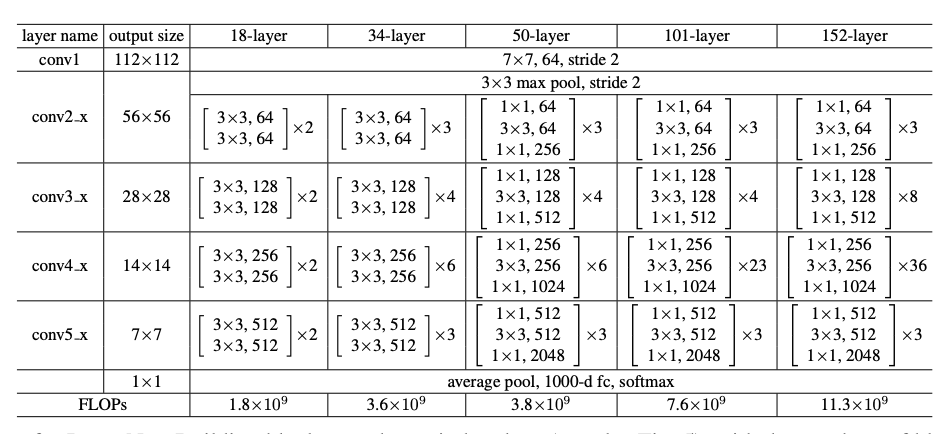
4.1 不同配置的ResNet结构
-
网络输入是ImageNet图像,短边在[256,480]中随机选取,然后resize到224×224尺寸,输入网络。
-
conv2_x:表示第二个卷积模块,x表示模块里有很多层。
-
[3 × 3, 64]
[3 × 3, 64]× 3: []内的是一个残差块,其卷积核大小为3*3,channel=64。×3表示有两个这样的残差层。
ResNet34结构图:(3+4+6+3)=16个残差模块,每个模块两层卷积层。再加上第一个7×7卷积层和最后一个全连接层,一共是34层。
4.2 残差结构效果对比
从下图可以看到有残差模块,网络收敛会更快,而且精度会更好:
4.3 残差结构中,输入输出维度不一致如何处理
- A. pad补0,使维度一致;
- B. 维度不一致的时候,使其映射到统一维度,比如使用全连接或者是CNN中的1×1卷积(输出通道是输入的两倍)。
- C. 不管输入输出维度是否一致,都进行投影映射。下面作者对这三种操作进行效果验证。从下面结果可以看到,B和C效果差不多,都比A好。但是做映射会增加很多复杂度,考虑到ResNet中大部分情况输入输出维度是一样的(也就是4个模块衔接时通道数会变),作者最后采用了方案B。

4.4 深层ResNet引入瓶颈结构Bottleneck
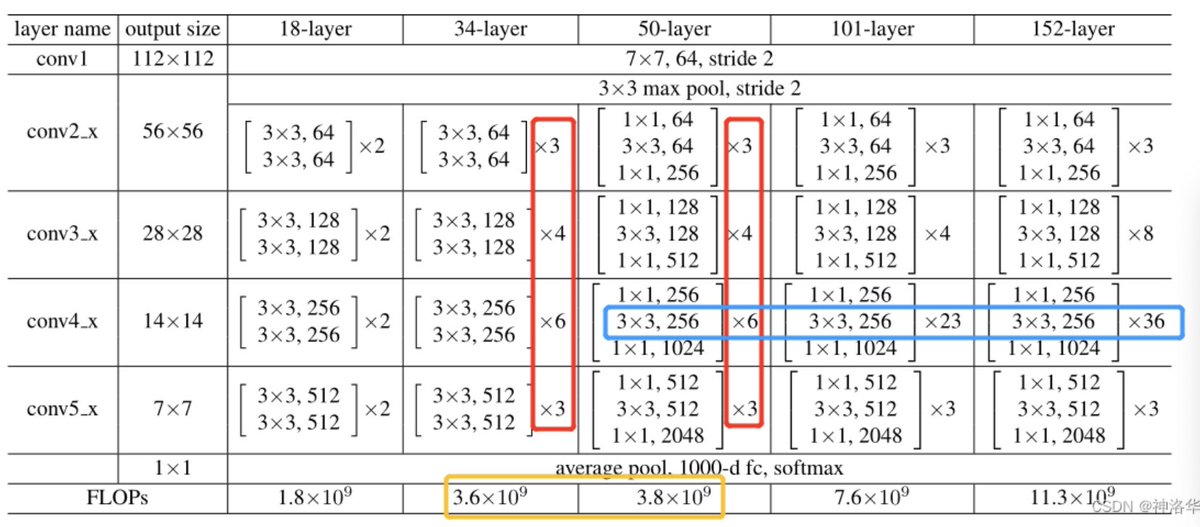
在ResNet-50及以上的结构中,模型更深了,可以学习更多的参数,所以通道数也要变大。比如前面模型配置表中,ResNet-50/101/152的第一个残差模块输出都是256维,增加了4倍。
如果残差结构还是和之前一样,计算量就增加的太多了(增加16倍),划不来。所以重新设计了Bottleneck结构,将输入从256维降为64维,然后经过一个3×3卷积,再升维回256维。这样操作之后,复杂度和左侧图是差不多的。这也是为啥ResNet-50对比ResNet-34理论计算量变化不大的原因。(实际上1×1卷积计算效率不高,所以ResNet-50计算还是要贵一些)

5.代码实现
resnet中残差块有两种:(use_1x1conv=True/False):
- 步幅为2 ,高宽减半,通道数增加。所以shortcut连接部分会加一个1×1卷积层改变通道数
- 步幅为1,高宽不变
1 | import torch |
6.结论
ResNet就是在CNN主干上加了残差连接,这样如果新加的层训练效果不好的话,至少可以fallback变回简单模型,所以精度不会变差。
在现在来看,ResNet训练的比较快,是因为梯度保持的比较好。因为新加的层容易导致梯度消失(或者梯度爆炸),但是加了残差连接,梯度多了一部分,包含了之前层的梯度,这样不管加了多深,梯度会保持的比较大(主要是不会梯度消失,学不动),不会太快收敛,SGD跑得多就训练的比较好。(SGD的精髓就是,只要梯度比较大,就可以一直训练。反正有噪音,慢慢的总是会收敛,最后效果就会比较好)
为什么在cifar-10这样一个小的数据集上(32*32图片5w张)训练1202层的网络,过拟合也不是很厉害。为何transformer那些模型几千亿的参数不会过拟合,李沐认为是加了残差连接之后,模型内在复杂度大大降低了。(理论上模型加一些层,模型也至少可以将后面的层学成恒等映射,使精度不会变差。但实际上没有引导做不到这一点。所以本文才会显示的把残差结构加进去,使模型能够更容易的训练出来。比如后面层都是0,前面一些层才学到东西,也就是更容易训练出一个简单模型来拟合数据,所以加入残差连接等于是模型复杂度降低了)
残差网络ResNet
残差网络在设计之初,主要是服务于卷积神经网络(CNN),在计算机视觉领域应用较多,但是随着CNN结构的发展,在很多文本处理,文本分类里面(n-gram),也同样展现出来很好的效果。
1.网络深度为什么重要?
我们知道,在CNN网络中,我们输入的是图片的矩阵,也是最基本的特征,整个CNN网络就是一个信息提取的过程,从底层的特征逐渐抽取到高度抽象的特征,网络的层数越多也就意味这能够提取到的不同级别的抽象特征更加丰富,并且越深的网络提取的特征越抽象,就越具有语义信息。
2.为什么不能简单的增加网络层数?
对于传统的CNN网络,简单的增加网络的深度,容易导致梯度消失和爆炸。针对梯度消失和爆炸的解决方法一般是正则初始化(normalized initialization)和中间的正则化层(intermediate normalization layers),但是这会导致另一个问题,退化问题,随着网络层数的增加,在训练集上的准确率却饱和甚至下降了。这个和过拟合不一样,因为过拟合在训练集上的表现会更加出色。
3.梯度消失和梯度下降
梯度爆炸和梯度消失问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
梯度爆炸:很多大数相乘 梯度消失:很多小于1的数字相乘
4.正则化
在机器学习中,正则化是正则化系数的过程,即对系数进行惩罚,通过向模型添加额外参数来防止模型过度拟合,这有助于提高模型的可靠性、速度和准确性。可以这么说,正则化本质上是为了防止因网络参数过大导致模型过拟合的泛化技术
正则化的作用和意义: 在于防止过度拟合。当发生过拟合时,模型几乎失去了泛化能力。这意味着该模型仅适用于训练它的数据集,而不能被用于其他数据集。
正则化的原理:正则化通过向复杂模型添加带有残差平方和(RSS)的惩罚项来发挥作用
正则化的类型:
- dropout:在dropout中,激活的随机数会更有效地训练网络。激活是将输入乘以权重时得到的输出。如果在每一层都删除了激活的特定部分,则没有特定的激活会学习输入模型。这意味着输入模型不会出现任何过度拟合。
- 批量归一化: 批量归一化通过减去批量均值并除以批量标准差来设法归一化前一个激活层的输出。它向每一层引入两个可训练参数,以便标准化输出乘以gamma和beta。gamma和beta的值将通过神经网络找到。通过弱化初始层参数和后面层参数之间的耦合来提高学习率,提高精度,解决协方差漂移问题。
- 数据扩充:数据扩充涉及使用现有数据创建合成数据,从而增加可用数据的实际数量。通过生成模型在现实世界中可能遇到的数据变化,帮助深度学习模型变得更加精确。
- 提前停止:使用训练集的一部分作为验证集,并根据该验证集衡量模型的性能。如果此验证集的性能变差,则立即停止对模型的训练。
- L1正则化:使用L1正则化技术的回归模型称为套索回归。Lasso回归模型即Least Absolute Shrinkage and Selection Operator,将系数的“绝对值”作为惩罚项添加到损失函数中。
- L2正则化:使用L2正则化的回归模型称为岭回归。岭回归模型即Ridge回归,在Ridge回归中系数的平方幅度作为惩罚项添加到损失函数中。
5.退化问题
按照常理更深层的网络结构的解空间是包括浅层的网络结构的解空间的,也就是说深层的网络结构能够得到更优的解,性能会比浅层网络更佳。但是实际上并非如此,深层网络无论从训练误差或是测试误差来看,都有可能比浅层误差更差,这也证明了并非是由于过拟合的原因。导致这个原因可能是因为随机梯度下降的策略,往往解到的并不是全局最优解,而是局部最优解,由于深层网络的结构更加复杂,所以梯度下降算法得到局部最优解的可能性就会更大。
6.如何解决退化问题
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。好吧,你不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
对于一个堆积层结构(几层堆积而成)当输入为x时其学习特征标记为H(x),现在我们希望其可以学习到残差F(x)=H(x)-x,这样其实原始的学习特征是F(x)+x。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。
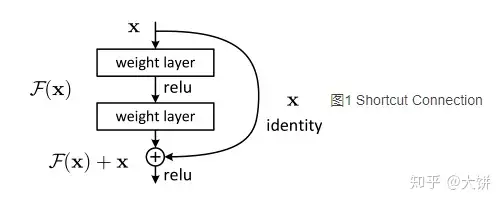
为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
- : 第l个残差单元的输入和输出,每个残差单元包含多层结构
- F: 残差函数,表示学习到的残差
- : 表示恒等映射
- f: RELU激活函数
根据上述,可以得到浅层l到深层L的学习特征为:
根据链式规则,可以求得反向过程梯度:
7.ResNet的tensorflow实现
1 | class ResNet50(object): |