
参考链接
- 一文浅析transformer–李沐带你深入浅出transformer
- 归一化层(Normalization layers)
- Batch Normalization
- Layer Normalization
- Instance Normalization:The Missing Ingredient for Fast Stylization
- Group Normalization
- DIFFERENTIABLE LEARNING-TO-NORMALIZE VIA SWITCHABLE NORMALIZATION
正文
归一化层,目前主要有这几个方法,Batch Normalization(2015年)、Layer Normalization(2016年)、Instance Normalization(2017年)、Group Normalization(2018年)、Switchable Normalization(2018年);
将输入的图像shape记为[N, C, H, W],这几个方法主要的区别就是在:
| 方法 | 归一化维度 | 特点 |
|---|---|---|
| BatchNorm | NHW | 在batch上归一化,小batchsize效果不佳 |
| LayerNorm | CHW | 在通道方向上归一化,对RNN作用明显 |
| InstanceNorm | HW | 在图像像素上归一化,适用于风格化迁移 |
| GroupNorm | 分组的CHW | 将channel分组后归一化 |
| SwitchableNorm | BN/LN/IN | 结合BN、LN、IN,赋予权重,网络自学习归一化方法选择 |

Batch Noirmalization
首先,在进行训练之前,一般要对数据做归一化,使其分布一致,但是在深度神经网络训练过程中,通常以送入网络的每一个batch训练,这样每个batch具有不同的分布;此外,为了解决internal covarivate shift问题,这个问题定义是随着batch normalizaiton这篇论文提出的,在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。
所以batch normalization就是强行将数据拉回到均值为0,方差为1的正太分布上,这样不仅数据分布一致,而且避免发生梯度消失。
此外,internal corvariate shift和covariate shift是两回事,前者是网络内部,后者是针对输入数据,比如我们在训练数据前做归一化等预处理操作。

加入缩放平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。
1 | 注:BatchNorm2d的情况则是在每个通道C上计算H、W和N的均值和方差,即每个通道上的N张图像所有像素计算均值和方差。 |
Layer Normalization
batch normalization存在以下缺点:对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作。

BN与LN的区别在于:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
- BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。LN用于RNN效果比较明显,但是在CNN上,不如BN
BN VS LN
Batch Normalization:在特征d/通道维度做归一化,即归一化不同样本的同一特征。缺点是:
- 计算变长序列时,变长序列后面会pad 0,这些pad部分是没有意义的,这样进行特征维度做归一化缺少实际意义。
- 序列长度变化大时,计算出来的均值和方差抖动很大。
- 预测时使用训练时记录下来的全局均值和方差。如果预测时新样本特别长,超过训练时的长度,那么超过部分是没有记录的均值和方差的,预测会出现问题。
Layer Normalization:在样本b维度进行归一化,即归一化一个样本所有特征。
- NLP任务中一个序列的所有token都是同一语义空间,进行LN归一化有实际意义
- 因为实是在每个样本内做的,序列变长时相比BN,计算的数值更稳定。
- 不需要存一个全局的均值和方差,预测样本长度不影响最终结果。
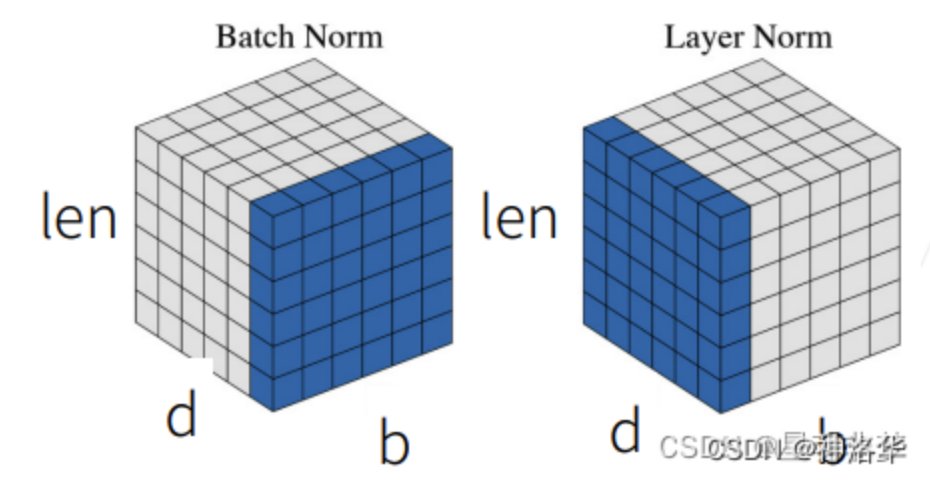
二维情况下的对比
BatchNorm:
我们模拟简单的二维的情况:每一行是一个样本 X,每一列是一个feature;
每次把一列(1 个 feature)放在一个 mini-batch 里,均值变成 0, 方差变成 1 的标准化
计算方法:(该列向量 - mini-batch 该列向量的均值)/(mini - batch 该列向量的方差)
训练时:mini-batch 计算均值;
测试时:使用 全局 均值、方差。
同样,BatchNorm 还会学 lambda和beta,BatchNorm 可以通过学习将向量 放缩成 任意均值、任意方差 的一个向量。
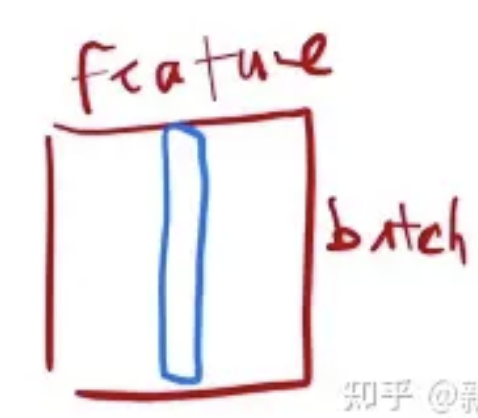
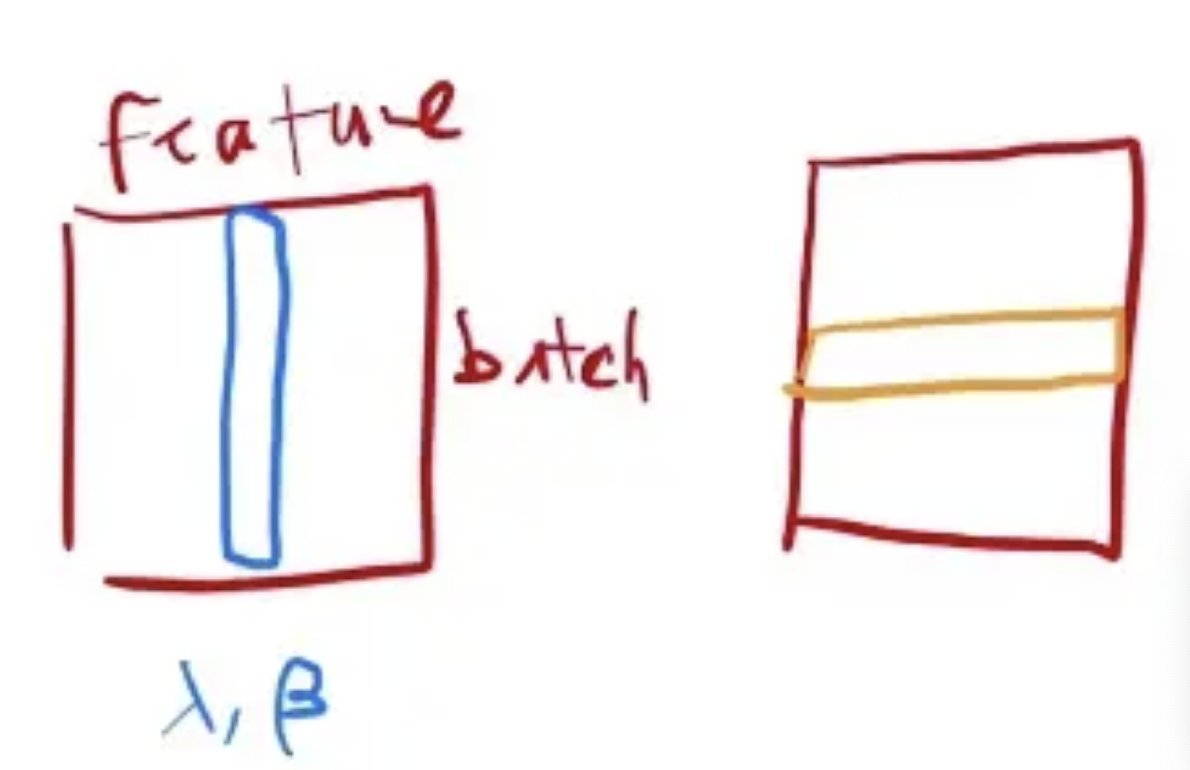
Layernorm:
同样模拟简单的二维输入:LayerNorm:对每个样本做 Normalization(把每一行变成 均值为 0、方差为 1),不是对每个特征做 normalization。
LayerNorm 在操作上 和 BatchNorm (二维输入) 的关系 :LayerNorm 整个把数据转置一次,放到 BatchNorm 里面出来的结果,再转置回去,基本上可以得到LayerNorm的结果。
上面在二维输入的情况下,简单的介绍了LN和BN之间的区别和联系,现在我们换到三维的输入来看一下。
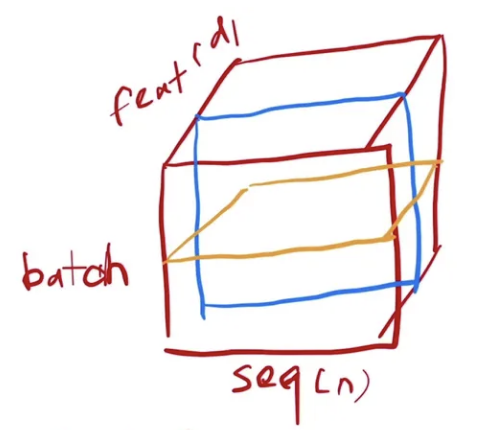
在transformer和RNN中,输入的维度经常是三维:一个句子有n个词,每个词对应一个向量,再加上batch size就是三维的了。
三维情况下的对比
列是sequence的输入的长度,为n。第三位是feature,是每个词的向量,在transformer里这个维度d=512。
在三维输入的情况下,BN和LN的计算逻辑:
BN:每次取一个维度的特征,蓝色框表示,拉成一个向量,均值为0,方差为1进行标准化。
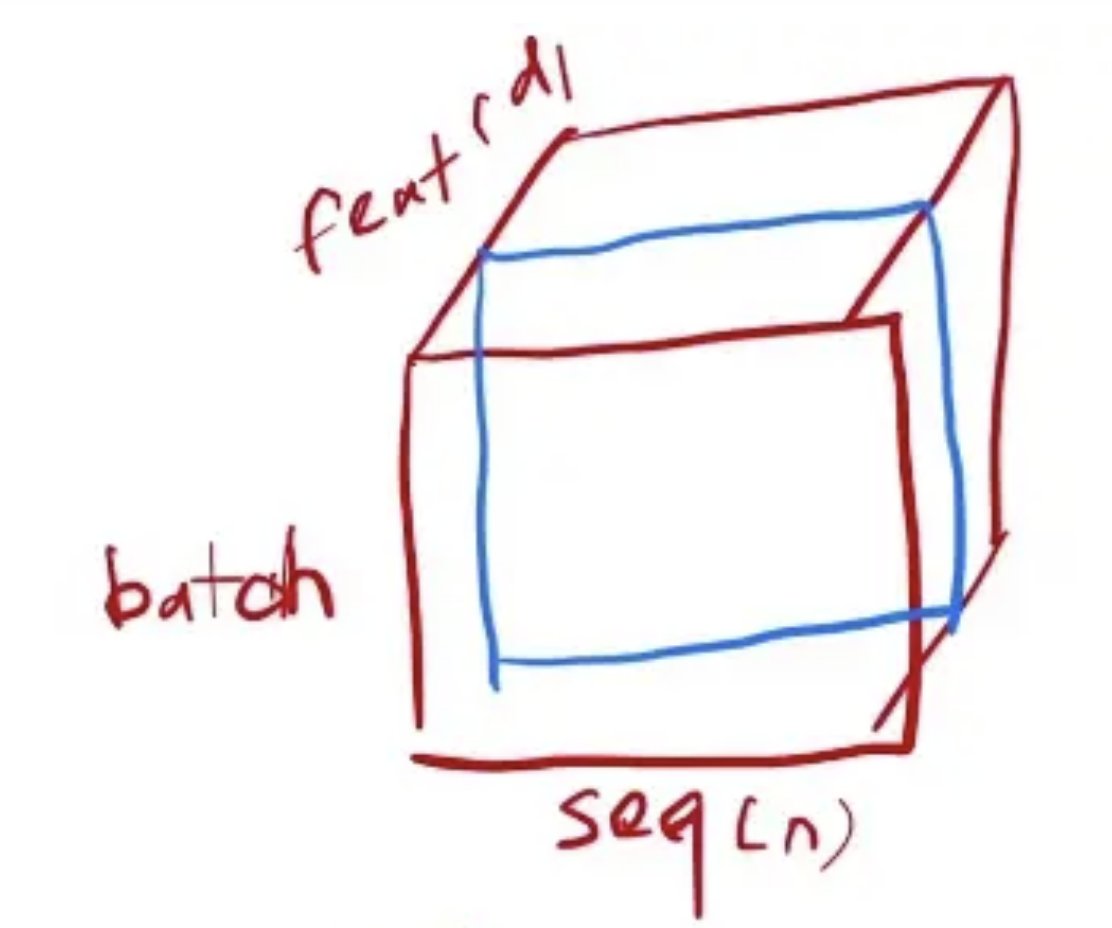
LN:从抽取一个特征,变成抽取一个样本,如黄色线表示
举例分析
为什么在时序数据中,LN的使用比BN更多呢?因为在时序样本中,可能很多的样本他们的长度都不一致。

举例分析:以四个样本为例:
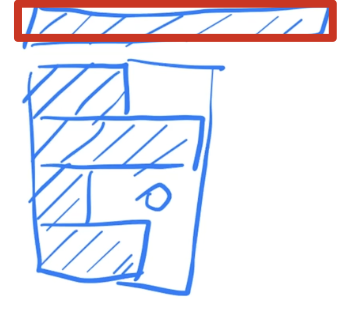
BN切出来的结果:
BatchNorm 计算均值和方差,有效的是阴影部分,其余是 0。
Mini-batch 的均值和方差:如果样本长度变化比较大的时候,每次计算小批量的均值和方差,均值和方差的抖动大。全局的均值和方差:测试时遇到一个特别长的全新样本 (红框),训练时未见过,训练时计算的均值和方差可能不好用。
LN切出来的结果如下:LayerNorm 每个样本自己算均值和方差,不需要存全局的均值和方差。LayerNorm 更稳定,不管样本长还是短,均值和方差是在每个样本内计算。

Instance Normalization
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。
但是图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
和BatchNorm的区别:

Group Normalization
主要是针对Batch Normalization对小batchsize效果差,GN将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值,这样与batchsize无关,不受其约束。
Normalization layer的作用
没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,但是使用了BN,就不用小心的调参了,较大的学习率极大的提高了学习速度;
- Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等;
- 另外,个人认为,batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。
BatchNorm为什么NB呢,关键还是效果好。不仅仅极大提升了训练速度,收敛过程大大加快,还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果。另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。