
参考链接
- transformer模型— 20道面试题自我检测
- Transformer常见问题与回答总结
- Transformer论文逐段精读【论文精读】
- 为什么Transformer 需要进行 Multi-head Attention?
- transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值?
- Breadcrumbstransformers/src/transformers
/modeling_bert.py
位置编码:
- 一文读懂Transformer模型的位置编码
- 浅谈Transformer模型中的位置表示
- Transformer改进之相对位置编码(RPE)
- 如何优雅地编码文本中的位置信息?三种positioanl encoding方法简述
面试十问
1. Transformer为何使用多头注意力机制?(为什么不使用一个头)
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
捕捉多种依赖关系:不同的注意力头可以学习到序列中不同位置之间的不同依赖关系。一个头可能专注于捕捉语法依赖,另一个头可能专注于语义依赖,这样模型就能够更全面地理解输入数据。
提高模型容量:多头注意力机制增加了模型的容量,使得模型能够学习到更复杂的表示。
更好的泛化能力:由于多头注意力机制能够从多个角度分析输入数据,模型的泛化能力得到提升。
并行计算:多头注意力机制的计算可以并行进行,这提高了训练和推理的效率。
2. Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
理解自注意力机制:Q、K、V的角色
您可能好奇,为什么在‘K’和‘Q’很相似的情况下(主要区别在于权重W_k和W_Q),还要创建一个单独的‘Q’?使用‘K’自身进行点乘似乎就足够了,这样不仅省去了创建和更新‘Q’的麻烦,还节约了内存空间。
(上图是自注意力公式,涉及Q、K、V三个向量。)
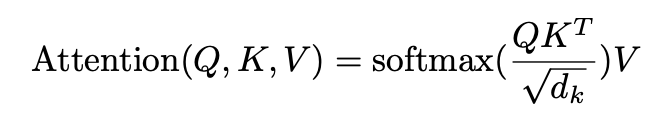
为了解答这个问题,我们首先要理解为什么计算Q和K的点乘是关键的。
- 点乘的本质:从物理意义上讲,两个向量的点乘代表了这两个向量的相似度。
- Q、K、V的物理意义:Q、K、V在物理上都代表了由同一个句子中不同token组成的矩阵。这些矩阵中的每一行都是一个token的词嵌入向量。例如,在句子“Hello, how are you?”中,长度为6,嵌入维度为300,那么Q、K、V都将形成一个(6, 300)的矩阵。
简单来说,K和Q的点乘是为了计算句子中每个token相对于其他token的相似度,这种相似度可以理解为注意力得分。
例如,在处理“Hello, how are you?”这句话时,当前token为“Hello”,我们可以计算出“Hello”与句子中的“,”、“how”、“are”、“you”、“?”这些token的注意力得分。有了这个注意力得分,我们就能知道在处理“Hello”时,模型关注了句子中的哪些token。

这个注意力得分是一个(6, 6)的矩阵。每一行代表一个token相对于其他token的关注度。例如,上图中的第一行代表了“Hello”这个单词相对于本句中其他单词的关注度。添加softmax函数是为了对关注度进行归一化。
虽然我们通过各种计算得到了注意力得分矩阵,但它很难直接代表原始句子。然而,'V’仍然代表原始句子,因此我们将这个注意力得分矩阵与’V’相乘,得到的是一个加权后的结果。最初,'V’中的每个单词仅通过词嵌入来表示,彼此之间没有关联。但经过与注意力得分相乘后,'V’中每个token的向量(即每个单词的词嵌入向量)在每个维度(每一列)上都根据其他token的关注度进行了调整。这一步相当于提纯,使每个单词关注其应关注的部分。
现在,我们来解释为什么不使用相同的值来代表K和Q。从以上解释中,我们知道K和Q的点乘旨在产生一个注意力得分矩阵,用于提纯’V’。K和Q使用不同的W_k和W_Q进行计算,这可以理解为在不同的空间上进行投影。正是因为这种不同空间的投影,提高了表达能力,使得计算出的注意力得分矩阵具有更高的泛化能力。我的理解是,由于K和Q使用了不同的W_k和W_Q,所以它们形成了两个完全不同的矩阵,因此具有更强的表达能力。但如果不使用Q,而是直接使用K与K进行点乘,你会发现注意力得分矩阵是一个对称矩阵。这意味着它们都在相同的空间中进行了投影,因此泛化能力较差。这样的矩阵在提纯’V’时的效果也不会很好。
3. Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
| 特性 / 类型 | 点乘注意力(Dot-product Attention) | 加法注意力(Additive Attention) |
|---|---|---|
| 公式 | Attention(Q, K, V) = softmax((QK^T) / sqrt(d_k)) V |
Attention(Q, K, V) = softmax(score(Q, K)) V |
| 输入 | 查询(Q)、键(K)和值(V) | 查询(Q)、键(K)和值(V) |
| 计算特点 | 使用查询和键的点乘来计算相似度 | 使用自定义的分数函数来计算查询和键之间的相似度 |
| 优点 | - 高效:点乘操作可以在硬件上高效并行化 - 强大的建模能力:能够捕捉查询和键之间的细微相似度 |
- 对长序列的性能可能优于点乘注意力 - 可能更适合处理复杂的分数函数 |
| 缺点 | - 维度高时可能导致梯度消失问题 - 需要适当缩放以防止softmax输出极端值 |
- 计算复杂度高:需要为每对查询和键计算分数 - 计算速度可能较慢 |
| 计算复杂度 | O(n^2 * d),其中n是序列长度,d是维度 | O(n^2 * d),但常数因子可能更大 |
| 效果 | - 在多数任务中表现良好 - 在硬件上更易于并行化,计算更快 |
- 在某些长序列任务中可能表现更好 - 适合复杂的相似度计算 |
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
self-attention的公式如下:
这里我们引用一下Transformer论文中的解释:
1 | While for small values of d_k, the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of d_k. We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1/√dk. |
通过上面内容,可以将该思考题分为两部分进行描述:
- 问题1: Transformer的计算Attention时为什么要除以一个数
- 问题2: 这个数为什么是
问题1: Transformer的计算Attention时为什么要除以一个数
当 很大的时候, 的结果里面会有很大,如果不进行scale,softmax将会作用于一些很大的值,那么根据softmax函数的分布,大多数值会堆积在分布的两端、也就是那些分布曲线平缓、梯度很小的地方,梯度很小就会导致梯度消失。
问题2: 这个数为什么是1/√dk
设文中提出的向量 (, )和 (, )都是相互独立的、均值为0,方差为1的随机变量,那么根据独立变量性质有:
因为有
所以在softmax之前除以 可以将 的分布的方差缩小至1。
这样一来,大部分数值都会分布在softmax梯度适当的位置,也就避免了梯度消失的问题。
实验验证
以下是用于实验的Python代码:
1 | from scipy.special import softmax |
实验结果:通过散点图展示,对比了不同实验条件下梯度最大绝对值分量的分布:
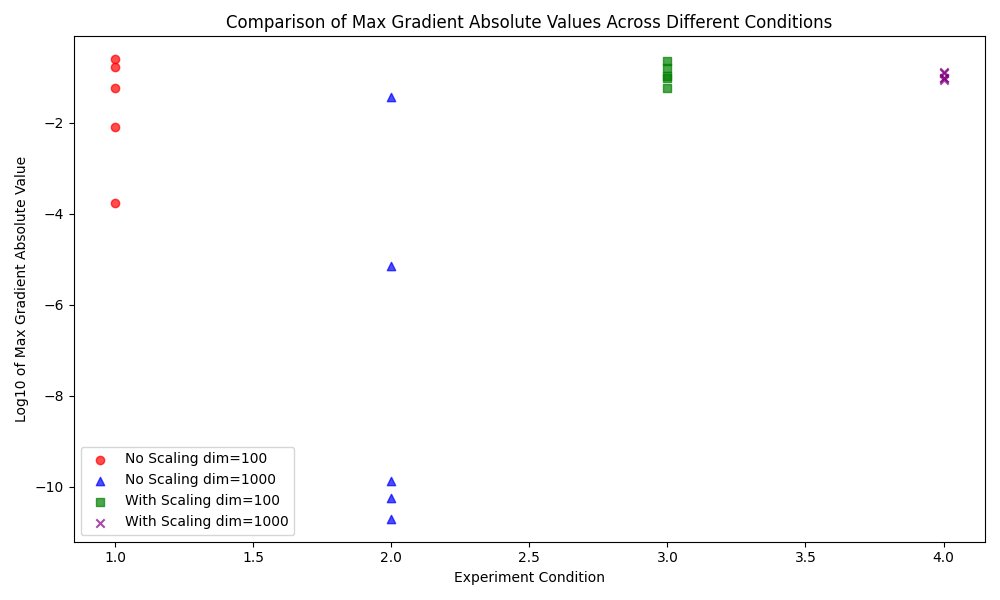
实验结果对比分析:
不带scaling的结果(维度=1000): 在没有缩放处理的情况下,维度为1000的实验组中,梯度的最大绝对值分量出现了极小的值,如1.8829382497642655e-11,这表明在高维空间中不进行缩放可能会导致梯度消失。这是因为在高维空间中,点积的结果通常会非常大,导致softmax函数饱和,从而在反向传播时梯度接近于零。
不带scaling的结果(维度=100): 在维度为100时,没有缩放处理的情况下,梯度的最大绝对值分量显得较大且变化范围宽,比如从0.059398546712975064到0.2498360169388831。这表明在较低维度的空间中,梯度消失的问题不像在高维空间那么显著。
带scaling的结果(维度=1000和100): 在应用了缩放处理后,无论是维度为1000还是100的情况下,梯度的最大绝对值分量都较为稳定,没有出现接近于零的情况。例如,维度为1000时的输出值在0.08899382001739972到0.1312868174831885之间。这表明通过缩放可以有效避免梯度消失,确保了梯度流的稳定性。
5. 在计算attention score的时候如何对padding做mask操作?
padding位置置为负无穷(一般来说-1000就可以),再对attention score进行相加。
步骤:
-
创建一个掩码矩阵: 对于输入序列中的每个位置,如果该位置是填充词,则在掩码矩阵的对应位置放置一个非常大的负数(如-1e9),否则放置0。
-
应用掩码矩阵: 将掩码矩阵加到注意力分数上。因为掩码矩阵中填充词的位置是非常大的负数,加上它们之后,这些位置的注意力分数也会变成非常大的负数。
-
应用softmax函数: 在加了掩码的注意力分数上应用softmax函数。由于填充词位置的分数是非常大的负数,经过softmax函数后,这些位置的权重将接近于0,而其他位置的权重将保持不变(因为softmax是一个归一化函数)。
-
计算加权和: 使用softmax的输出作为权重,计算值(Value)的加权和。
6. 为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
7. 大概讲一下Transformer的Encoder模块?
基本结构:
- Embedding + Position Embedding
- Self-Attention
- Add + LN
- FN
- Add + LN
Transformer的Encoder模块是由一系列相同的层堆叠而成的,每一层都有两个主要的子模块:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Position-wise Feed-Forward Networks)。此外,每个子模块周围都有一个残差连接,并且每个子模块的输出都会经过层归一化(Layer Normalization)。下面是对这些组件的详细说明:
-
1.多头自注意力机制(Multi-Head Self-Attention):这个模块可以使网络在进行预测时考虑输入序列的不同位置,对不同位置的输入分配不同的注意力。多头注意力机制意味着模型有多组不同的注意力参数,每组都会输出一个注意力权重,这些注意力权重会被合并成最终的注意力输出。
-
2.残差连接(Residual Connection): 残差连接帮助避免了深度神经网络中的梯度消失问题。在Transformer中,每个子模块的输出是 LayerNorm(x + SubLayer(x)),其中SubLayer(x)是子模块自身(比如多头自注意力或前馈神经网络)的输出。
-
3.层归一化(Layer Normalization): 层归一化是在模型的训练过程中加速收敛的一种技术,它对层的输入进行归一化处理,使得其均值为0,方差为1。
-
4.前馈神经网络(Position-wise Feed-Forward Networks): 这个模块由两个线性变换组成,中间夹有一个ReLU激活函数。它对每个位置的词向量独立地进行变换。
-
5.位置编码(Position Encoding): 由于Transformer模型没有循环或卷积操作,为了让模型能够利用词的顺序信息,需要在输入嵌入层中加入位置编码。位置编码和词嵌入相加后输入到Encoder模块。
整体来看,Transformer的Encoder模块将输入序列转换为一系列连续表示,这些表示在后续的Decoder模块中用于生成输出序列。每一层的Encoder都对输入序列的所有位置同时进行操作,而不是像RNN那样逐个位置处理,这是Transformer模型高效并行处理的关键。
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
9. 简单介绍一下Transformer的位置编码?有什么意义和优缺点?
Transformer模型采用自注意力机制处理序列数据。与传统的循环神经网络(RNN)和长短时记忆网络(LSTM)不同,Transformer不依赖于序列的递归处理,因此无法直接捕捉到序列中的位置信息。为了解决这个问题,Transformer引入了位置编码(Positional Encoding)的概念,将位置信息添加到模型的输入中。
位置编码是一个与词嵌入维度相同的向量,它被加到词嵌入上,以提供关于单词在序列中位置的信息。位置编码的公式如下:
对于位置pos和维度i,位置编码的第i个元素被定义为:
其中,d是词嵌入的维度,pos是词在序列中的位置,i是维度的索引。
优点:
- 固定模式: 位置编码是根据绝对位置计算的,而且是固定的,这意味着模型在训练和测试时使用相同的位置编码,保持一致性。
- 可推广性: 由于位置编码是基于三角函数计算的,它能够处理比训练时见过的序列更长的输入。
- 并行计算: 与RNN和LSTM不同,Transformer模型能够利用位置编码一次性处理整个序列,这使得模型能够充分利用现代硬件的并行计算能力,显著提高训练和推断的速度。
缺点:
- 固定长度: 尽管位置编码能够处理长序列,但是它们是根据固定长度计算的,这意味着如果序列太长,位置编码可能会失效。
- 可能需要更多的训练数据: 由于位置信息是通过位置编码隐式提供的,模型需要从数据中学习如何最好地利用这些信息,这可能需要更多的训练数据。
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
| 位置编码技术 | 优点 | 缺点 |
|---|---|---|
| 学习的位置编码 | 模型可以学习到最适合特定任务的位置编码,可能在某些任务上表现更好。 | 需要更多的参数和训练数据。 不能很好地泛化到训练时未见过的更长序列。 |
| 相对位置编码 | 能够更好地处理序列的局部结构,因为它关注的是元素之间的相对位置。 | 计算更复杂,可能增加训练和推理的时间。 |
| 固定但可学习的位置编码 | 能够在保持一定泛化能力的同时,适应特定任务的需求。 | 仍然需要更多的参数。 |
| 轴向位置编码 | 参数更少,更高效。 | 可能损失一些表达能力。 |
| Transformer-XL中的位置编码 | 能够更好地处理长序列,并捕捉长范围的依赖关系。 | 结构更复杂,计算成本更高。 |
11.简单讲一下Transformer中的残差结构以及意义。
在Transformer中的每个子层(如自注意力层和前馈神经网络层)后面,都会有一个残差连接,然后是一个层归一化(Layer Normalization)操作。具体来说,如果我们将子层的操作表示为(F(x)),那么残差连接的输出就是(x + F(x))。这里的(x)是子层的输入,(x + F(x))是残差连接的输出,也是下一层的输入。
残差结构的意义
- 缓解梯度消失: 残差连接允许梯度直接流过网络,这有助于缓解深层网络中常见的梯度消失问题,从而使得模型更容易训练。
- 提升训练速度: 残差连接提供了一种直接的信息传播路径,可以加速训练过程。
- 增强网络能力: 通过允许信息直接传递,残差连接使网络能够学习到更复杂的表示,增强了模型的能力。
- 增加网络深度: 残差结构使得训练非常深的网络成为可能,而不用担心梯度消失或者训练难度的问题。
- 保持前向信息的完整性: 由于残差连接的加法操作,即使某个子层没有学到有用的信息(或者学到了错误的信息),输入信息x也仍然能够通过残差连接传到下一层,这有助于保持前向传播过程中信息的完整性。
12. 为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
这个我会单独写
13. 简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
Transformer 中的前馈神经网络(Feed-Forward Neural Network, FFN)是模型每个注意力头后的一个重要组成部分。这个前馈神经网络对每个位置的词向量进行相同的操作,但它并不在不同位置间共享参数。
1 | ReLU(x) = max(0, x) |
其中,W_1, W_2, b_1, b_2 是网络参数,x 是输入的词向量,通常维度为 d_model。第一个线性层将输入从 d_model 维扩展到 d_ff 维,然后应用激活函数,再通过第二个线性层将维度从 d_ff 缩减回 d_model。
优点:
- 非线性:前馈神经网络引入了非线性变换,增加了模型的表达能力,使得 Transformer 能够学习到更复杂的函数映射。
- 并行计算:由于前馈神经网络对每个位置的操作是独立的,所以可以高效地进行并行计算,提高训练和推理的速度。
- 简单高效:前馈神经网络结构简单,计算效率高,易于优化。
缺点:
- 局限性:前馈神经网络在处理序列数据时只能考虑单个位置的信息,无法捕捉序列中的上下文关系。这种局限性通过 Transformer 中的自注意力机制来解决。
- 参数量大:尽管结构简单,但前馈神经网络中参数量较大,特别是当
d_ff很大时,这可能导致过拟合和增加模型的计算负担。
14.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
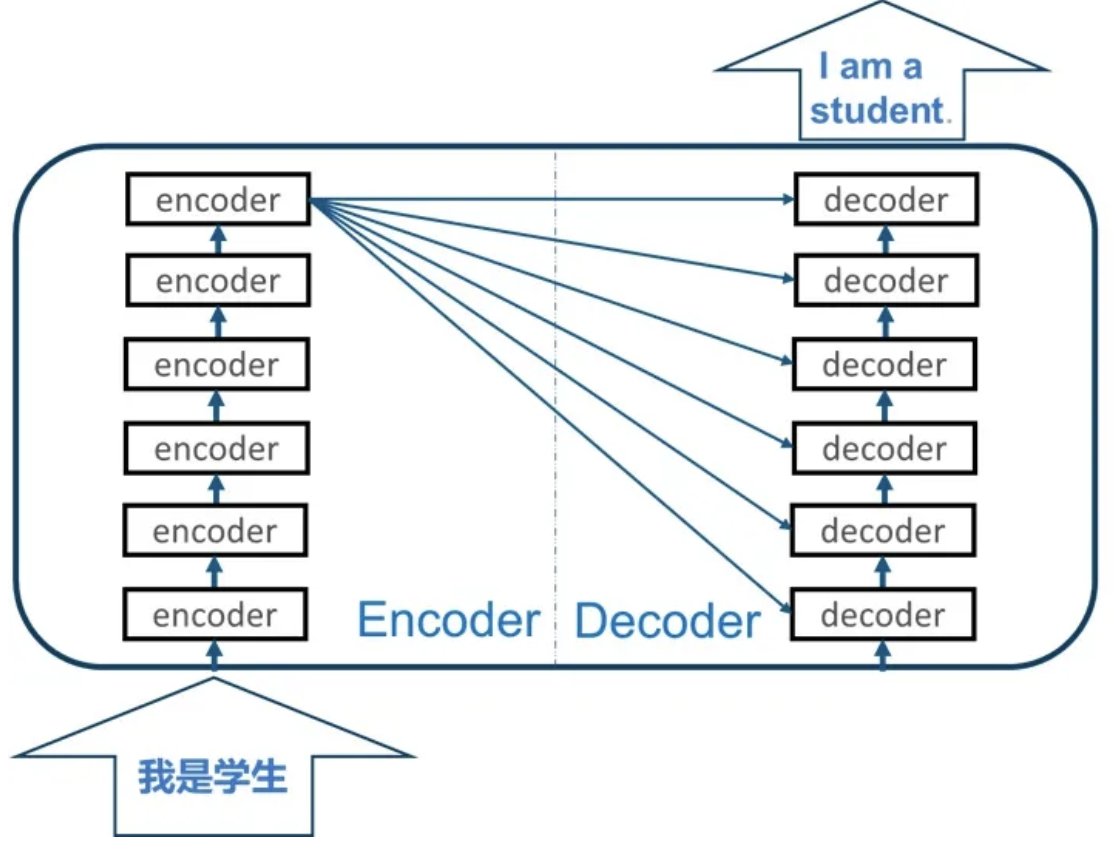
Encoder和Decoder之间的交互主要通过交叉注意力机制实现。具体来说:
查询来自Decoder:在交叉注意力层中,查询(Query)来自于Decoder的上一层的输出。
键和值来自Encoder:键(Key)和值(Value)来自于Encoder的输出。
通过计算查询与键的相似度,模型可以为每个Encoder输出分配一个权重,然后将这些权重应用于值,以产生一个加权和,该加权和将用作交叉注意力层的输出,并输入到下一层。
这种机制使Decoder能够关注输入序列的不同部分,特别是在生成每个新单词时。例如,在机器翻译任务中,当模型生成目标语言的一个单词时,它可以通过这种机制来聚焦于源语言句子中的相关部分。
15.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
Encoder的多头自注意力 :在Encoder的多头自注意力中,每个位置都可以自由地注意序列中的所有其他位置。这意味着计算注意力分数时,并没有位置上的限制。这种设置是因为在编码阶段,我们假定有完整的输入序列,并且每个词都可以依赖于上下文中的任何其他词来获得其表示。
Decoder的多头自注意力(带掩码):在Decoder的多头自注意力中,为了保持自回归属性(即生成当前词只依赖于前面的词),我们需要确保在计算注意力分数时,每个位置只能注意到它前面的位置。为了实现这一点,我们使用了序列掩码(sequence mask)的技术。
具体来说,序列掩码是在注意力分数计算之前,将当前位置之后所有位置的分数设置为一个非常大的负数(通常是负无穷)。这样,在接下来的softmax操作中,这些位置的注意力权重将变为0,确保模型不会注意到这些位置。
1 | 为什么需要Decoder自注意力进行序列掩码? |
16.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
17. Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
Transformer模型通常使用一种特殊的学习率调度策略,称为“Noam”学习率预热策略。具体来说,学习率随着训练的进行先增大后减小,计算公式为:
其中,是模型的隐藏层大小, step_num是当前的训练步数,warmup_steps是预热的步数。这种学习率调度策略有助于模型在训练初期快速收敛,同时在训练后期通过减小学习率来稳定训练。
Dropout是一种正则化技术,用于防止神经网络过拟合。在Transformer模型中,Dropout被应用在以下几个地方:
-
在注意力权重计算后,用于随机“丢弃”一些权重,以防止模型过分依赖某些特定的输入。
-
在每个子层(自注意力层,前馈神经网络层等)的输出后,用于防止过拟合。
-
在词嵌入层和位置编码的加和后。
Dropout率(即随机丢弃的神经元比例)是一个超参数,需要根据具体任务进行调整。常见的取值范围在0.1到0.3之间。
在测试(或推理)阶段,通常会禁用Dropout,确保所有的神经元都参与到计算中,以获得最稳定的模型输出。这是因为Dropout在训练时引入了随机性,而在测试时我们希望模型的表现是确定的。在许多深度学习框架中,可以通过设置模型为评估模式来自动禁用Dropout。
18. 一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系