
1.量化是什么
简而言之,所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。简单直白点讲,即原来表示一个权重需要使用float32表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,我们就可以获得接近4倍的网络加速!
2.为什么需要做模型量化
随着深度学习技术在多个领域的快速应用,具体包括计算机视觉-CV、自然语言处理-NLP、语音等,出现了大量的基于深度学习的网络模型。这些模型都有一个特点,即大而复杂、适合在N卡上面进行推理,并不适合应用在手机等嵌入式设备中,而客户们通常需要将这些复杂的模型部署在一些低成本的嵌入式设备中,因而这就产生了一个矛盾。为了很好的解决这个矛盾,模型量化应运而生,它可以在损失少量精度的前提下对模型进行压缩,使得将这些复杂的模型应用到手机、机器人等嵌入式终端中变成了可能。
随着模型预测越来越准确,网络越来越深,神经网络消耗的内存大小成为一个核心的问题,尤其是在移动设备上。通常情况下,目前的手机一般配备 4GB 内存来支持多个应用程序的同时运行,而三个模型运行一次通常就要占用1GB内存。
模型大小不仅是内存容量问题,也是内存带宽问题。模型在每次预测时都会使用模型的权重,图像相关的应用程序通常需要实时处理数据,这意味着至少 30 FPS。因此,如果部署相对较小的 ResNet-50 网络来分类,运行网络模型就需要 3GB/s 的内存带宽。网络运行时,内存,CPU 和电池会都在飞速消耗,我们无法为了让设备变得智能一点点就负担如此昂贵的代价。
3.模型量化的动机
-
更少的存储开销和带宽需求。即使用更少的比特数存储数据,有效减少应用对存储资源的依赖,但现代系统往往拥有相对丰富的存储资源,这一点已经不算是采用量化的主要动机;
-
更快的计算速度。即对大多数处理器而言,整型运算的速度一般(但不总是)要比浮点运算更快一些;
-
更低的能耗与占用面积。
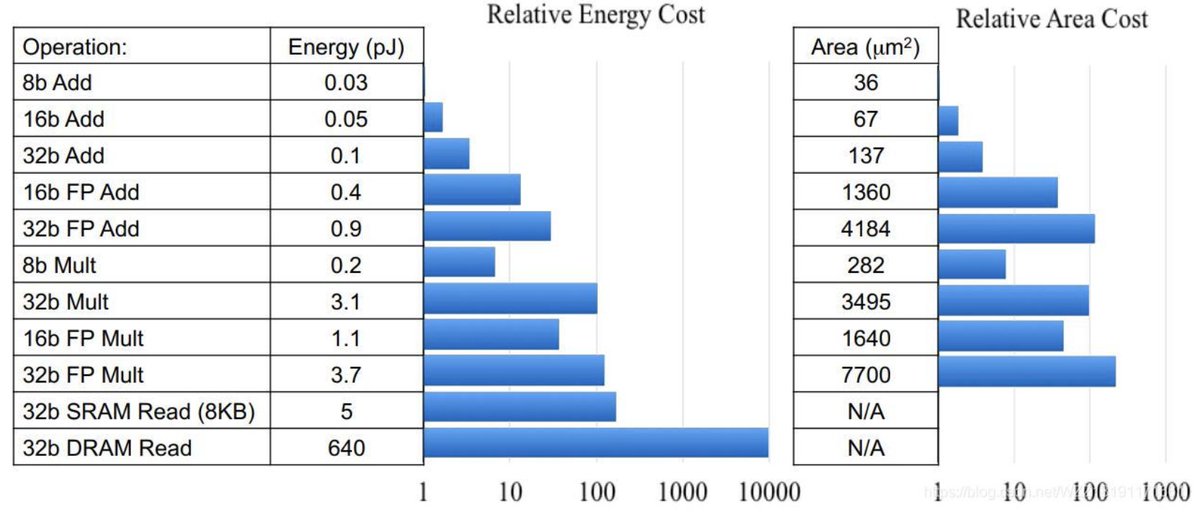
从上图中可以看到,FP32乘法运算的能耗是INT8乘法运算能耗的18.5倍,芯片占用面积则是int8的27.3倍,而对于芯片设计和FPGA设计而言,更少的资源占用意味着相同数量的单元下可以设计出更多的计算单元;而更少的能耗意味着更少的发热,和更长久的续航。
-
尚可接受的精度损失。即量化相当于对模型权重引入噪声,所幸CNN本身对噪声不敏感(在模型训练过程中,模拟量化所引入的权重加噪还有利于防止过拟合),在合适的比特数下量化后的模型并不会带来很严重的精度损失。按照gluoncv提供的报告,经过int8量化之后,ResNet50_v1和MobileNet1.0 _v1在ILSVRC2012数据集上的准确率仅分别从77.36%、73.28%下降为76.86%、72.85%。
-
支持int8是一个大的趋势。即无论是移动端还是服务器端,都可以看到新的计算设备正不断迎合量化技术。比如NPU/APU/AIPU等基本都是支持int8(甚至更低精度的int4)计算的,并且有相当可观的TOPs,而Mali GPU开始引入int8 dot支持,Nvidia也不例外。除此之外,当前很多创业公司新发布的边缘端芯片几乎都支持int8类型。