
参考链接
- 🔗:纯加法Transformer!结合脉冲神经网络和Transformer的Spike-driven Transformer (NeurIPS 2023)
- 🔗:NeurIPS 2023 | 结合脉冲神经网络和Transformer的纯加法Transformer
- 🔗:Spike-Driven-Transformer
- 🔗:NeurIPS 2023 | 结合脉冲神经网络和Transformer的纯加法Transformer
- 🔗:NeurlPS 2023 | 纯加法Transformer!
Abstract
脉冲神经网络 (SNN) 凭借其独特的基于脉冲的事件驱动(即脉冲驱动)范例,提供了一种节能的深度学习选项。在本文中,我们将脉冲驱动范式融入到transformer中,提出的脉冲驱动变压器具有四个独特的属性:
- i)事件驱动,当变压器的输入为零时不触发计算;
- ii) 二进制脉冲通信,所有与脉冲矩阵相关的矩阵乘法都可以转化为稀疏加法;
- iii)在代币和通道维度上具有线性复杂度的自注意力;
- iv) 脉冲形式的 Query、Key 和 Value 之间的操作是掩码和加法。
总之,Spike-driven Transformer 中只有稀疏的加法运算。为此,我们设计了一种新颖的 SpikeDriven Self-Attention (SDSA),它仅利用掩码和加法运算,而不进行任何乘法,因此计算能量比普通 self-attention 低 87.2 倍。特别是在SDSA中,Query、Key和Value之间的矩阵乘法被设计为掩码运算。此外,我们在激活函数之前重新排列了普通 Transformer 中的所有残差连接,以确保所有神经元传输二进制脉冲信号。结果表明,Spikedriven Transformer 在 ImageNet-1K 上可以达到 77.1% 的 top-1 精度,这是 SNN 领域最先进的结果。源代码可在 Spike-driven Transfromer 处获取。
Introduction
仿生脉冲神经网络(SNN)最重要的计算特征之一是基于脉冲的事件驱动(spike-driven):
- i) 当计算是事件驱动时,它会作为事件稀疏触发(带有地址信息的脉冲)发生;
- ii)如果仅采用二进制脉冲(0 或 1)用于脉冲神经元之间的通信,则网络的操作是突触累加(AC)。当在 TrueNorth [2]、Loihi [3] 和 Tianjic [4] 等神经形态芯片上实现 SNN 时,任何时刻只有一小部分脉冲神经元处于活动状态,其余的则处于空闲状态。因此,仅执行稀疏加法运算的脉冲驱动的神经形态计算被认为是传统人工智能的有前途的低功耗替代方案[5-7]
虽然snn在生物可信性和能量效率方面具有明显优势,但其应用受到较差的任务精度的限制。transformer的自注意力在各种任务中表现出很高的性能[8-10]。将Transformer的有效性与snn的高能量效率相结合是一个自然而令人兴奋的想法。在这个方向有一些研究,但到目前为止都依赖于“混合计算”。即现有的脉冲Transformer中都存在由vanilla Transformer组件主导的乘加(MAC)操作和由脉冲神经元引起的AC操作。一种流行的方法是将Transformer中的一些神经元替换为脉冲神经元来执行各种任务[11-22],并保留mac所需的操作,如点积、softmax、缩放等。
尽管混合计算有助于减少将脉冲神经元添加到Transformer中带来的精度损失,但从SNN的低能量成本中获益可能具有挑战性,特别是考虑到电流脉冲Transformer几乎无法在神经形态芯片上使用。为解决这个问题,本文提出一种新的脉冲驱动Transformer,在整个网络中实现了SNNs的脉冲驱动性质,同时具有出色的任务性能。Transformer的两个核心模块,Vanilla Self-Attention (VSA)和多层感知器(MLP),被重新设计成脉冲驱动的范式。
VSA的三个输入矩阵是Query (Q)、Key (K)和Value (V)(图1(a))。Q和Kfirst进行相似度计算得到注意图,其中包括矩阵乘法、scale和softmax三个步骤。然后使用注意力图对V(另一个矩阵乘法)进行加权。当前脉冲transformer[20,19]中典型的脉冲自注意力将在执行两个类似于inVSA的矩阵乘法之前将Q, K, V转换为脉冲形式。区别在于spike矩阵乘法可以转化为加法运算,而softmax不需要[20]。但这些方法不仅在输出中产生大整数(因此需要额外的尺度乘法来进行归一化,以避免梯度消失),而且未能充分利用脉冲驱动范式与自注意力相结合的能量效率潜力。
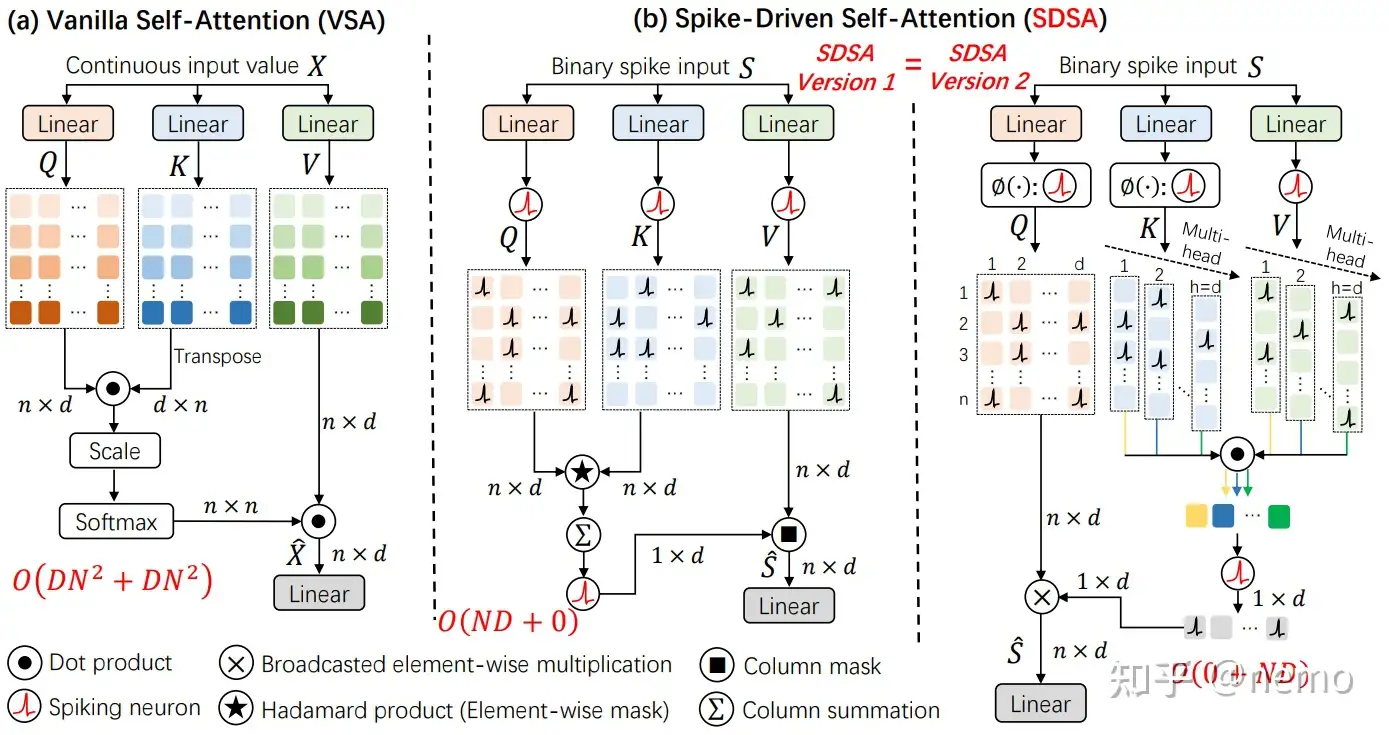
图1:普通自注意力(VSA)和我们的脉冲驱动自注意力(SDSA)的比较(a)是典型的普通自注意力(VSA)[8]。(b)是两个等价的SDSA版本。SDSA的输入是二元尖峰信号。在SDSA中,只有掩码和稀疏加法。版本1:Spike Q和K首先执行元素掩模,即Hadamard产品;然后采用列求和和spikenneuron层得到二值注意力向量;最后,将二值注意力向量应用于脉冲V以掩盖部分通道(特征)。版本2:Version1的等效版本(参见第3.3节)揭示了SDSA是一种独特的线性注意力类型(脉冲神经元层是核函数),其时间复杂度与token和通道维度都是线性的。通常,在VSA和SDSA中执行自注意力操作分别需要2N个2D乘累加和0.02N个Daccumulate操作,其中N是token的数量,D是通道维度,0.02是Q和K掩码后矩阵的非零比率。因此,脉冲Q、K和V之间的自注意力算子几乎没有能量消耗。
本文提出脉冲驱动自注意力(SDSA)来解决这些问题,包括两个方面(见图1(b)中的SDSA版本1):i)哈达玛乘积取代矩阵乘法;Ii)矩阵列求和和脉冲神经元层发挥softmax和scale的作用。前者可以认为不消耗能量,因为尖峰之间的哈达玛乘积与元素掩模等价。后者也几乎不消耗能量,因为要逐列求和的矩阵非常稀疏(通常,非零元素的比例小于0.02)。SDSA是一种特殊的线性注意力[23,24],即图1(b)的版本2。在这个视图中,将Q、K和V转换为脉冲形式的脉冲神经元层是一个核函数。
此外,现有的脉冲变压器[20,12]通常遵循SEW-SNN残差设计[25],其快捷方式是脉冲添加,从而输出多比特(整数)脉冲。这个快捷方式可以满足事件驱动,但引入了整数乘法。我们修改了整个Transformer架构中的残差连接,将其作为膜电位之间的捷径[26,27],以解决这个问题(第3.2节)。所提出的脉冲驱动Transformer提高了在静态和神经形态事件数据集上的任务精度。本文的主要贡献如下:
- 提出一种新的脉冲驱动Transformer,仅利用稀疏加法。这是脉冲驱动范式首次被纳入Transformer中,所提出的模型对神经形态芯片是硬件友好的。
- 设计了一种脉冲驱动的自注意力(SDSA)。spike Query, Key, Value之间的自注意力算子被mask和sparse加法代替,基本上没有能量消耗。SDSA在token和信道的计算上都是线性的。总的来说,SDSA的能量开销(包括查询、键和值生成部分)比原生的self-attention同类算法低87.2倍。
- 重新安排剩余连接,使脉冲驱动Transformer中的所有脉冲神经元都通过二进制脉冲通信。
- 广泛的实验表明,所提出的架构在静态和神经形态数据集上都可以优于或与最先进的(SOTA) snn相媲美。我们在ImageNet-1K上实现了77.1%的准确率,这是SNN领域的最高结果。