
学习链接
🔗:Transformer详解和自注意力机制 Self-attention
目录
- 1.Introduction
- 2.Self-attention
- 3.Multi-head Self-attention
- 4.Position Encoding
- 5.Transformer
- 5.1 Encoder
- 5.2 Decoder
- 5.3 Cross Attention
一.Introduction
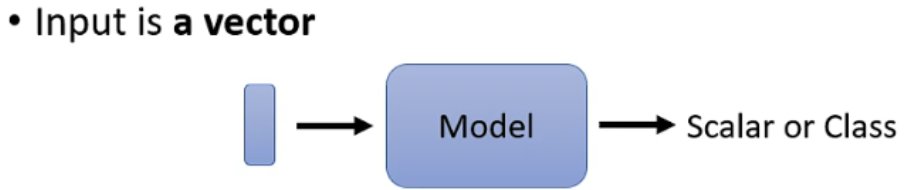
在过去的使用场景中,模型的输入通常只有一个单独的向量,而模型的输出则是预测的数值或类别,见下图:
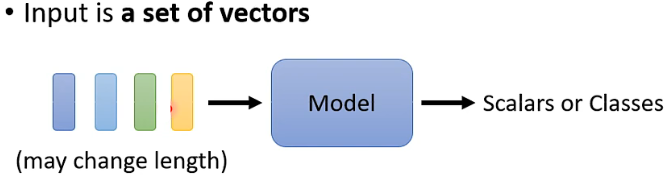
但是假设输入的是一排向量(或序列),且向量的长度不是固定的,例如声音信号、语句、基因序列等,如下图:
而对于模型输出而言,可以分为如下图所示的三种类型,即输入输出序列长度不变,只有一个输出和输出长度不确定:

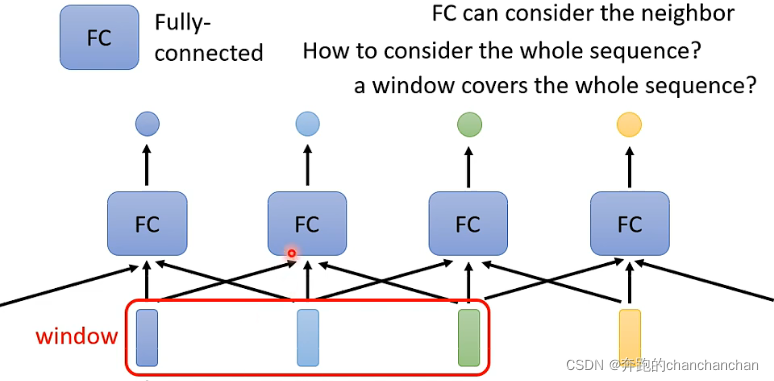
以第一种类型为例,常规的想法是采取各个击破的方法,给每个向量添加一个全连接层,从而得到我们想要的输出,但是这样的方法并没有考虑到各个输入向量之间的关系:

因此为了让全连接层能够考虑到上下文信息之间的关系,可以将多个相邻的输入向量或序列串联起来给到全连接层,但是到底需要多少个相邻的输入向量,以及如何能够把整个序列作为输入,这就是Self-attention所要做的工作。
二.Self-attention
Self-attention的内部机制大致如上图所示,每个输出都考虑了所有的输入。以单个输出为例,Self-attention的具体操作流程如下:

---------- Self-attention流程·BEGIN ----------
- : 两个输入向量之间的关联性
- : 经过softmax后,两个输入向量之间的关联性
- a:输入
- b:输出
- W:权重
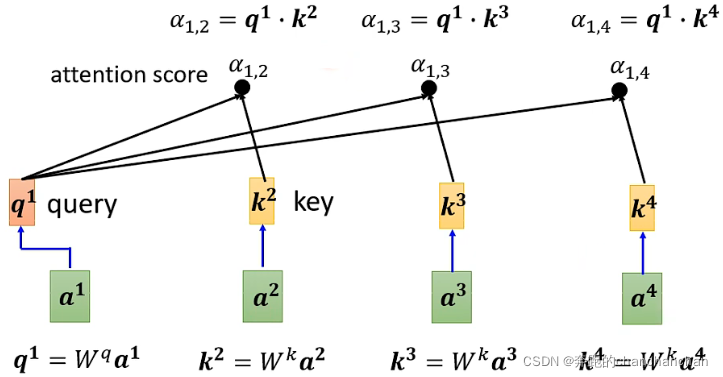
Step1: 将两个输入向量各自乘以,得到q和k,再将q和k做点乘,从而得到两个输入向量之间的关联性,记作 :

如下图所示,分别得到输入向量之间的关联性,输入向量和之间的关联性,输入向量和之间的关联性:
Step2: 通常情况下,还需要考虑输入向量和自身的关联性,然后将计算得到的所有关联性扔给softmax函数,得到:

Step3: 根据输入向量之间的关联性进一步提取向量中的重要信息,即将每个输入向量乘以得到,并与其相关的关联性分数相乘,最后将结果累加得到:

这样一来,假设输入向量的关联性比较大,即的值较大,根据累加得到的也会更接近
---------- Self-attention流程·END ----------
实际上,Self-attention的输出可以同时得到。从矩阵运算的角度来说,Self-attention的具体操作流程如下:
---------- Self-attention流程·矩阵角度·BEGIN ----------
Step1: 将输入向量按列组合成一个矩阵I,与相乘得到矩阵Q,其中矩阵Q包含了所有输入向量对应的query,同理可以得到key和value对应的矩阵K和V:
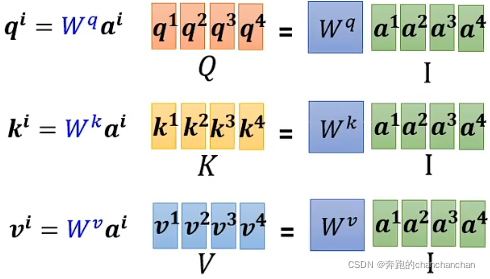
Step2: 将各个向量对应的key按行组合,与输入向量相乘,得到与输入向量之间的所有关联性分数:
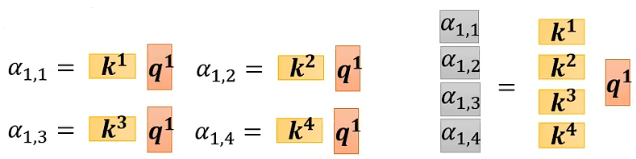
由此可知,将矩阵K转置后,与矩阵Q相乘得到矩阵A,其中矩阵A包含了所有输入向量之间的关联性分数:

然后再将矩阵A给到Softmax激活函数,得到矩阵:

Step3: 最后将各个输入向量对应的value按列组合成一个矩阵V,并与矩阵:
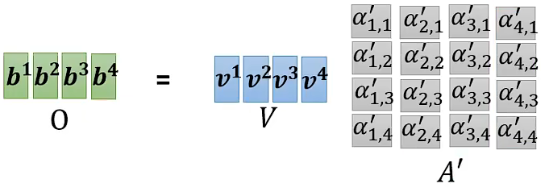
---------- Self-attention流程·矩阵角度·END ----------
三.Multi-head Self-attention
Multi-head Self-attention就是由多个单独的Self-attention堆叠而成,每个Self-attention之间具有独立的参数矩阵,相互之间不共享参数。
以2 heads为例,首先通过输入向量与矩阵相乘得到,再将向量与2个不同的矩阵相乘得到两个参数和
同理可以得到参数。对于另一个输入向量,同样可以得到两组参数。
在计算关联度分数时,只需先对第一类的参数进行计算,得到

再对第二类的参数进行计算,得到,如下图所示:
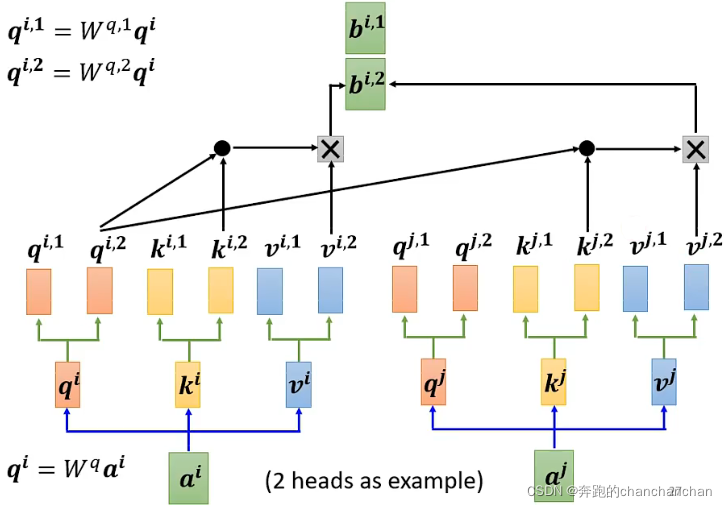
最后将和拼接起来,与矩阵相乘得到Multi-head Self-attention的第i个输出:

四.Position Encoding
由于在Self-attention的计算中不包含位置信息,因此为了加入位置信息,需要在每个位置都定义一个位置向量,并且直接加到输入向量上
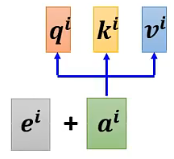
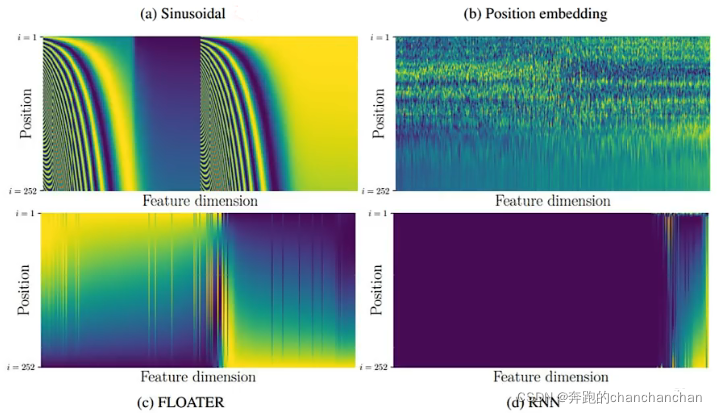
位置向量通常是手动设置,也可以通过学习得到:
五.Transformer
Transformer本质上是一个Sequence-to-sequence(Seq2seq) 的模型,它的输出序列长度不再是固定的,而是由模型自身决定:

Sequence-to-sequence(Seq2seq)的模型结构通常如上图所示,由Encoder对输入向量(或序列)进行处理,处理完之后给到Decoder,并由Decoder决定输出向量(或序列)
5.1 Encoder
其中Encoder部分的作用是给定一组向量(或序列),输出一组相同长度的向量(或序列):
根据原论文Attention Is All You Need中的介绍,进一步拆解它的内部结构可以看到,输入向量b经过Self-attention得到向量a,同时由相应的输入向量b通过跳跃连接与向量a相加,经过一次Layer Norm操作后得到向量c。将向量c给到全连接层得到向量d,并与自身通过跳跃连接相加得到向量e,最后再做一次Layer Norm操作得到向量f:

5.2 Decoder
根据Attention Is All You Need中的介绍,Decoder的内部结构可以看到:

在Decoder中,Encoder的输出在经过cross attention处理之后,来作为Decoder的输入,另外还需要给予一个one-hot形式的BEGIN信号让Decoder开始输出一个向量。
在NLP任务中,这个向量的长度由任务所需要的语言单词或短语的数量来决定,例如识别的语言是中文,那么这个向量可能就需要包含所有的中文汉字或常见字。同时为了让模型自己决定需要输出多长的序列,向量中还包含了一个END信号。向量中的每个单词或短语都带有对应的模型预测概率,概率最高的那一项才是最终的输出

接下来再将第一个输出给到Decoder,作为新的输入,从而得到第二个输出。以此为例,新的输出再次给到Decoder中,直到输出END信号表示向量输出的结束。
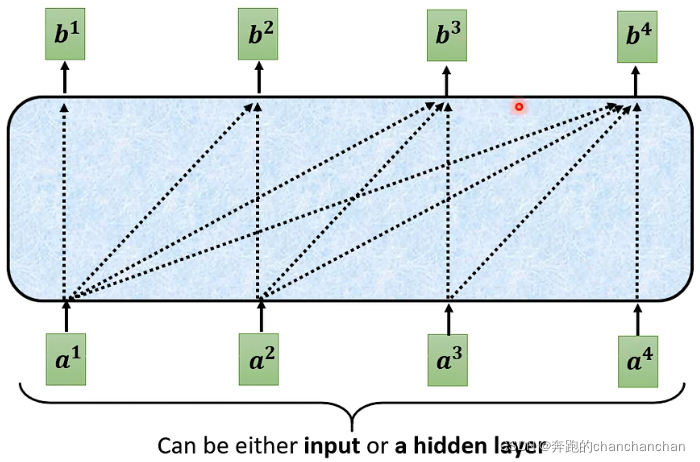
正是因为新的输入是由之前的输出所得到的,因此在Decoder中使用了Masked Multi-Head Attention,与Encoder中的Multi-Head Attention所不同的是,在计算输出的时候只考虑自身及其左边的输入向量,而不需要考虑右边那些还没得到的输入向量,如下图:
5.3 Cross Attention
Decoder部分不仅有自身的输入向量,还有Encoder部分的输出作为输入向量。而Encoder部分的输出与Decoder中Masked Multi-Head Attention的输出一起被送到Multi-Head Attetion进行处理,这部分就叫Cross Attention,如上图:
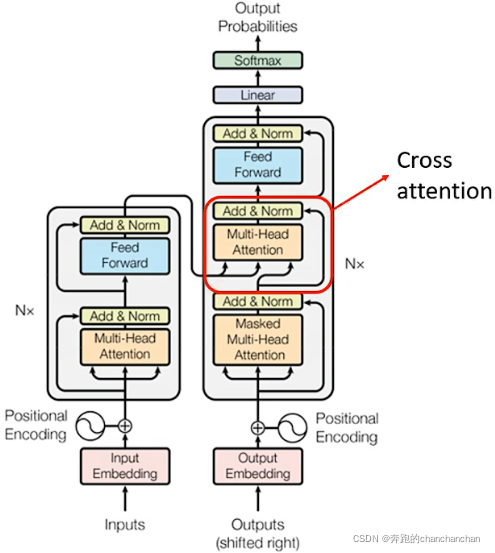
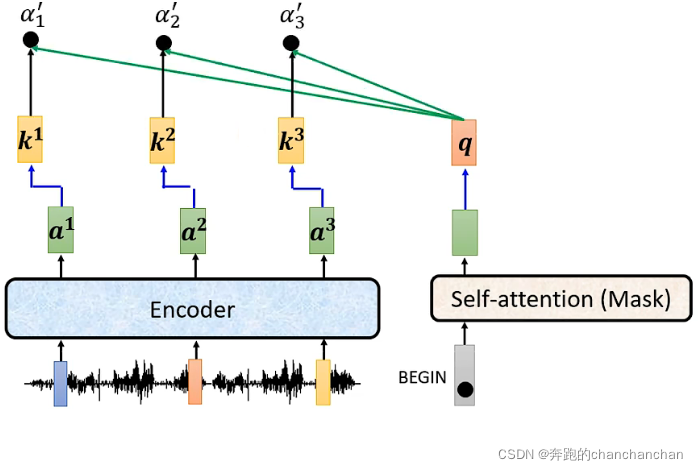
Cross Attention的具体实现流程如下:
---------- Cross Attention流程·BEGIN ----------
1.Encoder的输出分别与各自对应的矩阵相乘得到key值,Decoder中Masked Multi-Head Attention的输出与矩阵相乘得到query值,然后两者做点乘得到关联性分数:
2.Encoder的输出分别与各自对应的矩阵相乘得到value值,然后与关联性分数相乘,并将所有的结果累加起来。累加后的结果再给到全连接层,得到最终的输出:
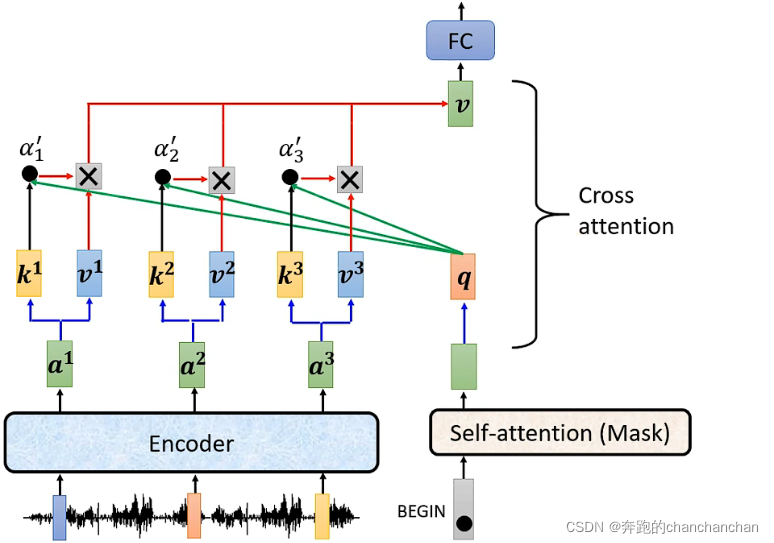
---------- Cross Attention流程·END ----------