
参考链接:
一.Review
1.1 1-of-N Encoding
最早采用的方法,显然一个词用一个向量表示不合理
apple=[1 0 0 0 0]
bag=[0 1 0 0 0]
cat=[0 0 1 0 0]
dog=[0 0 0 1 0]
elephant=[0 0 0 0 1]
1.2 Word Class
之后才用WOrd CLass,但是这种分类还是太粗糙了

1.3 Word Embedding
每一个词映射到一个连续的向量空间,语义相似的词语在向量空间中距离较近

1.4 Contextualized Word Embedding
但是同一个词汇可能有不同的意思,比如:
- Have you paid that money to the bank yet ?(银行)
- It is safest to deposit your money in the bank.(银行)
- The victim was found lying dead on the river bank.(河堤)
- They stood on the river bank to fish.(河堤)
期待:
- 过去,word type对应一种embedding;现在,word tokens对应一种的embdding
- 但同时word tokens也取决于其语境

二.ELMO=Embeddings from Language Model
- RNN-based language models
给很多句子去预测下一个句子的token是什么,不仅仅有正向的还有反向的

但是深层LSTM的每一层都可以生成一个潜伏的表示,我们该用哪个呢?

ELMO的思想那个就是我全部都要,不同的Task抽不同层的权重不一样:

三.BERT=Bidirectional Encoder Representations from Transformers

3.1 train approach
两种方法要同时使用
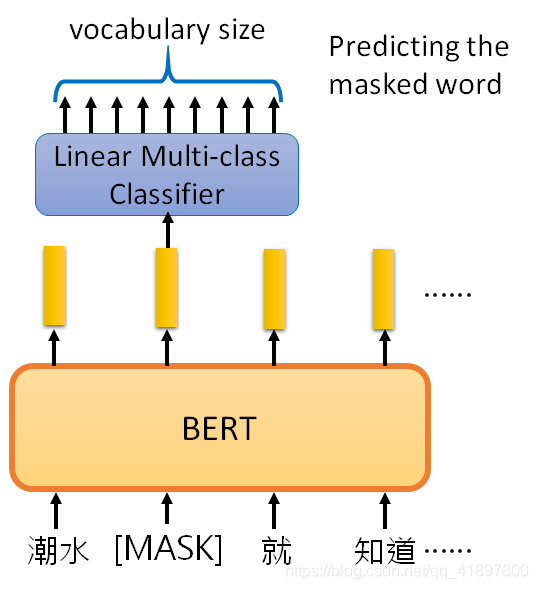
3.1.1 train approach:Masked LM
BERT模型本身就是Transformer的Encoder,输入输出长度一样,BERT会对输入随机mask一些token,然后让机器来填空。Mask有两种处理方法,一是将其标记为一个特殊的符号,二是随机填上一个文字。在下图的例子中,第二个output vector经过Linear transform和softmax之后,得到所有文字在第二个位置出现的概率,选择概率最大的文字为答案。训练目标就是最小化 预测结果与已知的ground truth之间的交叉熵
3.1.2 train approach:Next Sentence Prediction
BERT在做填空的同时,同时也在做NSP任务。对于输入的句子得做两个处理,首先在开始位置加上一个特殊的classification token(CLS),在两个句子之间加上一个分隔符(SEP)。然后将处理好的向量表示丢给BERT,只取出(CLS)token对应的输出向量,进行线性变换和softmax,来判断Sentence1的下一句是否为Sentence2,但是NSP任务对BERT的下游任务没有什么帮助
- (CLS):输出分类结果的位置
- (SEP):两个句子的边界

3.2 Pre-Train与fine-tune
BERT做填空题和NSP对于我们很关心的其他任务来说非常有用,并且这些任务只有少量带标签的数据,我们称训练BERT的过程称为预训练(pre-train),称我们关心的其他任务为下游任务(downstream tasks)。
BERT模型预训练之后,经过微调(fine-tune)之后,可以应用于各式各样的下游任务中。
3.3 How to use BERT
3.3.1 Case 1
- 输入:stence
- 输出:class
- 例如:情感分析,文件分类…

3.3.2 Case 2
- 输入:sentence
- 输出:每个词的class
- 例如:槽位填充

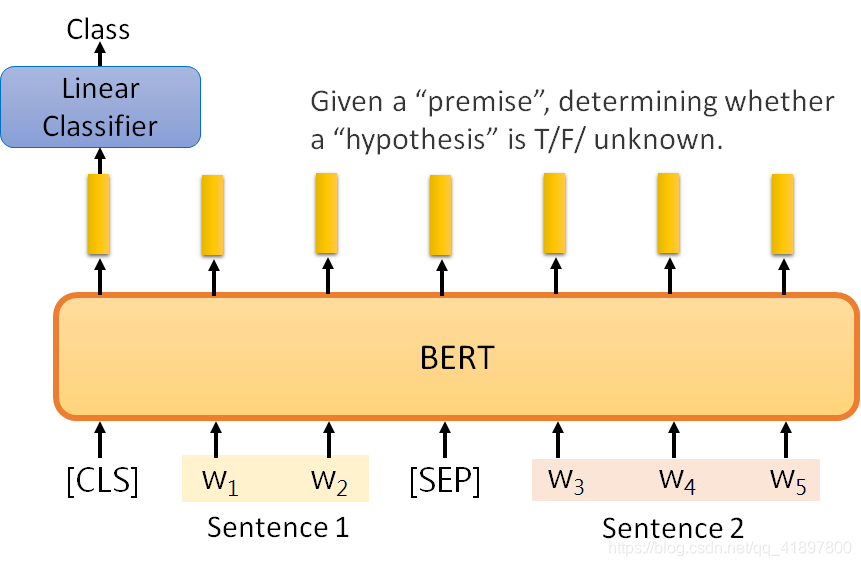
3.3.3 Case 3
- 输入:两个sentence
- 输出:class
- 例如:给定一个假设,判断推理是否正确
3.3.4 Case 4
- 输入:Document和Query
- 输出:两个正数s,e(s决定开始,e决定结束)
基于抽取的问答的限制是答案必须来自于文章。如下图,输入的document中有N个单词,输入的query或question中有M个单词,最后输出两个整数(s, e),分别表示答案在document中的起始(start)位置和结束(end)位置。例如第三题"within a cloud"是document的第77到79个单词,所以输出为(77, 79)。

具体如何训练,就是有两组随机初始化的向量,第一组与document对应的输出向量表示(output vector representation)做内积(inner product),其结果进行线性变换和softmax,选择最大概率0.5所在的位置为起始位置s=2;第二组做同样的操作,选择最大概率0.7所在的位置为结束位置e=3,所以 outpu=(2,3),answer=(d2,d3)

3.4 ERNIE=Enhanced Representation through Knowledge Integration
专门为中文设计的BERT
将Mask LM盖住的character改为盖住word

3.5 Multilingual BERT
Multi-BERT就是使用多种语言对BERT进行预训练,Multi-BERT使用了104种语言做预训练,实验发现Multi-BERT在一种语言上做微调,在另一种语言上做测试

4.GPT=Generative Pre-Training(GPT)
GPT是Generative Pre-trained Transformer的缩写。GPT做的事其实是Predict Next Token,顾名思义就是预测下一个token,模型示意如下:
